








Dalam dunia teknologi yang bergerak cepat, Large Language Models (LLM) telah menjadi pusat perhatian, menarik perhatian para peneliti, bisnis, dan penggemar teknologi. Model bahasa kolosal ini, dengan kapasitasnya yang luar biasa untuk memahami, menghasilkan, dan memanipulasi teks dalam skala besar, telah menarik minat individu dan organisasi yang ingin memanfaatkan kemampuannya. Dan kita melihat industri ini ramai dengan berbagai peluncuran, mulai dari perusahaan teknologi besar hingga perusahaan rintisan, semuanya berlomba untuk memantapkan diri di bidang ini, namun di balik kegembiraan seputar LLM, terdapat kenyataan bahwa memahami model-model ini bisa jadi cukup menantang. Model ini merupakan perpaduan kompleks antara teknologi canggih, wawasan berbasis data, dan pemrosesan bahasa alami yang rumit.
Dalam panduan ini, kami mengungkap misteri LLM dengan mempelajari aspek-aspek penting seperti cara kerjanya, aplikasi yang beragam di berbagai industri, kelebihan, keterbatasan, dan cara mengevaluasinya secara efektif. Jadi, mari selami dan jelajahi dunia LLM, temukan potensi dan dampaknya terhadap masa depan AI dan komunikasi.
Apa yang dimaksud dengan model bahasa besar (LLM)?
Model Bahasa Besar adalah model bahasa yang dikenal dengan skalanya yang besar, memungkinkan integrasi miliaran parameter untuk membangun jaringan saraf tiruan yang rumit, jaringan ini memanfaatkan potensi algoritme AI tingkat lanjut, menggunakan metodologi pembelajaran yang mendalam, dan menarik wawasan dari kumpulan data yang luas untuk tugas-tugas penilaian, normalisasi, pembuatan konten, dan prediksi yang akurat.
Jika dibandingkan dengan model bahasa konvensional, LLM menggunakan dataset yang sangat besar, yang secara substansial meningkatkan fungsionalitas dan kemampuan model AI. Meskipun istilah “besar” tidak memiliki definisi yang tepat, istilah ini umumnya mencakup model bahasa yang terdiri dari tidak kurang dari satu miliar parameter, yang masing-masing mewakili variabel pembelajaran mesin.
Sepanjang sejarah, bahasa lisan telah berevolusi untuk komunikasi, menyediakan kosakata, makna, dan struktur. Dalam AI, model bahasa memiliki peran yang sama sebagai fondasi untuk komunikasi dan menghasilkan ide. Silsilah LLM dapat ditelusuri kembali ke model AI awal seperti model bahasa ELIZA, yang memulai debutnya pada tahun 1966 di MIT di Amerika Serikat, dan banyak yang telah berubah sejak saat itu.
LLM modern memulai perjalanannya dengan menjalani pelatihan awal pada dataset tertentu dan kemudian berkembang melalui serangkaian teknik pelatihan, membina hubungan internal, dan memungkinkan pembuatan konten baru. Model bahasa berfungsi sebagai tulang punggung untuk aplikasi Pemrosesan Bahasa Alami (Natural Language Processing/NLP). Model bahasa memungkinkan pengguna untuk memasukkan pertanyaan dalam bahasa alami, sehingga menghasilkan respons yang koheren dan relevan.
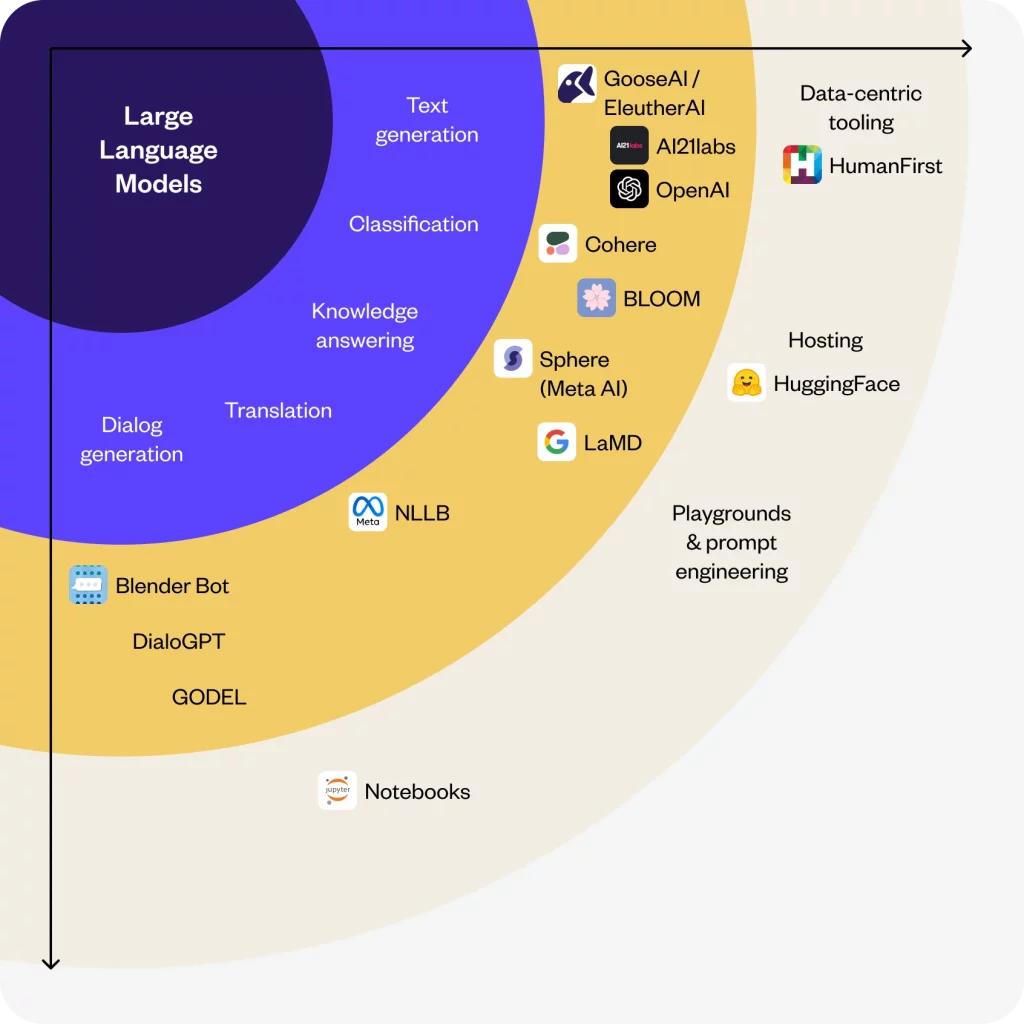
Apa perbedaan antara model bahasa besar dan AI Generatif?
LLM dan AI Generatif sama-sama memainkan peran penting dalam ranah kecerdasan buatan, tetapi keduanya memiliki tujuan yang berbeda dalam bidang yang lebih luas. LLM, seperti GPT-3, BERT, dan RoBERTa, dikhususkan untuk menghasilkan dan memahami bahasa manusia, menjadikannya bagian dari AI Generatif. AI Generatif, di sisi lain, mencakup spektrum model yang luas yang mampu menciptakan beragam bentuk konten, mulai dari teks, gambar, musik, dan banyak lagi.
Dengan demikian, LLM sekarang bersifat multimodal, yang berarti bahwa LLM dapat memproses dan menghasilkan konten dalam berbagai modalitas, seperti teks, gambar, dan kode. Ini adalah kemajuan yang signifikan dalam teknologi LLM, karena memungkinkan LLM untuk melakukan berbagai tugas yang lebih luas dan berinteraksi dengan dunia dengan cara yang lebih komprehensif. LLM multimodal seperti GPT-4V dan Kosmos-2.5, serta PaLM-E masih dalam tahap pengembangan, namun memiliki potensi untuk merevolusi cara kita berinteraksi dengan komputer.
Cara lain untuk memikirkan perbedaan antara AI generatif dan LLM adalah bahwa AI generatif adalah tujuan, sedangkan LLM adalah alat. Selain itu, perlu dicatat bahwa meskipun LLM adalah alat yang ampuh untuk membuat konten, namun LLM bukanlah jalan eksklusif untuk mencapai AI generatif. Model yang berbeda, seperti Generative Adversarial Networks (GAN) untuk gambar, Recurrent Neural Networks (RNN) untuk musik, dan arsitektur saraf khusus untuk pembuatan kode, ada untuk membuat konten di domain masing-masing.
Pada dasarnya, tidak semua alat AI generatif dibangun di atas LLM, tetapi LLM itu sendiri merupakan salah satu bentuk AI generatif.
Komponen utama dari model bahasa besar (LLM)
Untuk memahami cara kerja LLM, sangat penting untuk mempelajari komponen-komponen utamanya:
1. Transformator
LLM biasanya dibangun di atas fondasi arsitektur berbasis transformer, yang telah merevolusi bidang NLP. Arsitektur ini memungkinkan model untuk memproses teks input secara paralel, sehingga sangat efisien untuk tugas-tugas bahasa berskala besar.
2. Data Pelatihan
Tulang punggung LLM adalah korpus data teks yang sangat besar yang digunakan untuk melatihnya. Data ini terdiri dari teks internet, buku, artikel, dan sumber tekstual lainnya, yang mencakup berbagai bahasa dan domain.
3. Tokenisasi dan Prapemrosesan
Data teks diberi token, disegmentasi menjadi unit-unit diskrit seperti kata atau bagian subkata, dan diubah menjadi embedding numerik yang dapat digunakan oleh model. Tokenisasi adalah langkah penting untuk memahami konteks bahasa.
4. Mekanisme Perhatian
LLM memanfaatkan mekanisme perhatian untuk menetapkan tingkat kepentingan yang berbeda-beda pada bagian kalimat atau teks yang berbeda. Hal ini memungkinkan mereka menangkap informasi kontekstual secara efektif dan memahami hubungan antar kata.
5. Penyetelan Parameter
Menyempurnakan hiperparameter model, termasuk jumlah lapisan, unit tersembunyi, tingkat putus sekolah, dan tingkat pembelajaran, merupakan aspek penting dalam mengoptimalkan LLM untuk tugas-tugas tertentu.
Bagaimana cara kerja model bahasa besar (LLM)?
Fungsi LLM dapat dijelaskan melalui langkah-langkah mendasar berikut ini:
- Pengkodean Masukan: LLM menerima urutan token (kata atau unit subkata) sebagai input, yang diubah menjadi embedding numerik menggunakan embedding yang telah dilatih sebelumnya.
- Pemahaman Kontekstual: Model ini menggunakan beberapa lapisan jaringan saraf, biasanya berdasarkan arsitektur transformator, untuk menguraikan hubungan kontekstual antara token dalam urutan input. Mekanisme perhatian dalam lapisan-lapisan ini membantu model menimbang pentingnya kata-kata yang berbeda, memastikan pemahaman yang mendalam tentang konteks.
- Pembuatan Teks: Setelah memahami konteks input, LLM menghasilkan teks dengan memprediksi kata atau token yang paling mungkin muncul berdasarkan pola yang telah dipelajari. Proses ini diulang secara berulang untuk menghasilkan teks yang koheren dan relevan secara kontekstual.
- Pelatihan: LLM dilatih pada set data yang sangat besar, dan selama proses ini, parameter internalnya disesuaikan secara iteratif melalui backpropagation. Tujuannya adalah untuk meminimalkan perbedaan antara prediksi model dan data teks aktual dalam set pelatihan.
Sederhananya? Bayangkan LLM seperti koki yang sangat hebat di dapur yang sangat besar. Koki ini memiliki sejumlah besar bahan resep (parameter) dan buku resep yang sangat cerdas (algoritme AI) yang membantu menciptakan semua jenis hidangan. Mereka telah belajar dari memasak resep yang tak terhitung jumlahnya (kumpulan data yang luas) dan dapat dengan cepat menilai bahan apa yang akan digunakan, menyesuaikan rasa (penilaian dan normalisasi), membuat resep baru (pembuatan konten), dan memprediksi hidangan apa yang akan Anda sukai (prediksi yang tepat). LLM seperti seniman kuliner yang menghasilkan konten berbasis teks.
Mari kita ambil contoh kueri tentang “Saya ingin menulis keterangan postingan Instagram tentang perjalanan ke Spanyol.” dan pelajari lebih dalam tentang cara kerja LLM dalam hal ini:
Large Language Model (LLM) akan mulai dengan menandai kalimat input, memecahnya menjadi unit-unit individual seperti “saya”, “ingin”, “ke”, “menulis”, “sebuah”, “Instagram”, “memposting”, “keterangan”, “di”, “perjalanan”, “ke”, dan “Spanyol”. Kemudian akan menggunakan arsitektur pembelajaran yang mendalam, yang sering kali didasarkan pada transformer, untuk memahami konteks dan hubungan di antara token-token ini. Dalam kueri khusus ini, LLM akan mengenali niat pengguna untuk membuat keterangan postingan Instagram tentang bepergian ke Spanyol, dengan menggunakan data pelatihan ekstensif yang terdiri dari beragam korpora teks. Dengan memanfaatkan mekanisme perhatian, LLM akan memberikan nilai yang berbeda-beda pada kata-kata yang berbeda, dengan menekankan “Instagram”, “post”, “caption”, dan “Spanyol” sebagai komponen utama dari respons. Selanjutnya, model ini akan menghasilkan caption postingan Instagram yang relevan secara kontekstual dan koheren yang selaras dengan permintaan pengguna, yang merangkum esensi dari pengalaman perjalanan di Spanyol.
Kasus penggunaan model bahasa besar (LLM)
Keserbagunaan LLM telah menyebabkan pengadopsiannya dalam berbagai aplikasi baik untuk individu maupun perusahaan:
Pengkodean:
LLM dipekerjakan dalam tugas-tugas pengkodean, di mana mereka membantu pengembang dengan membuat cuplikan kode atau memberikan penjelasan untuk konsep pemrograman. Misalnya, LLM dapat menghasilkan kode Python untuk tugas tertentu berdasarkan deskripsi bahasa alami yang diberikan oleh pengembang.
Pembuatan konten:
Mereka unggul dalam penulisan kreatif dan pembuatan konten otomatis. LLM dapat menghasilkan teks yang mirip dengan manusia untuk berbagai tujuan, mulai dari membuat artikel berita hingga membuat salinan pemasaran. Misalnya, alat pembuat konten dapat menggunakan LLM untuk membuat postingan blog atau deskripsi produk yang menarik. Kemampuan lain dari LLM adalah penulisan ulang konten. Mereka dapat menyusun ulang atau menulis ulang teks dengan tetap mempertahankan makna aslinya. Hal ini berguna untuk menghasilkan variasi konten atau meningkatkan keterbacaan.
Selain itu, LLM multimodal dapat memungkinkan pembuatan konten teks yang diperkaya dengan gambar. Misalnya, dalam sebuah artikel tentang tujuan wisata, model ini dapat secara otomatis menyisipkan gambar yang relevan di samping deskripsi tekstual. Model ini juga dapat memungkinkan pembuatan konten teks yang diperkaya dengan gambar. Contohnya, model dapat secara otomatis menyisipkan gambar yang relevan dari tempat-tempat yang layak untuk dikunjungi bersama dengan deskripsi tekstualnya.
Peringkasan konten
Selain itu, LLM juga unggul dalam meringkas konten teks yang panjang, mengekstraksi informasi penting, dan memberikan ringkasan yang ringkas. Hal ini sangat berguna untuk memahami dengan cepat poin-poin utama dari artikel, makalah penelitian, atau laporan berita. Selain itu, hal ini dapat digunakan untuk membantu agen dukungan pelanggan dengan rangkuman tiket yang cepat, sehingga meningkatkan efisiensi dan meningkatkan pengalaman pelanggan.
Terjemahan bahasa:
LLM memiliki peran penting dalam penerjemahan mesin. Mereka dapat meruntuhkan hambatan bahasa dengan menyediakan terjemahan yang lebih akurat dan sesuai konteks antar bahasa. Misalnya, LLM multibahasa dapat menerjemahkan dokumen bahasa Prancis ke dalam bahasa Inggris dengan lancar sambil mempertahankan konteks dan nuansa aslinya.
Pencarian informasi:
LLM sangat diperlukan untuk tugas pencarian informasi. LLM dapat dengan cepat menyaring korpus teks yang luas untuk mendapatkan informasi yang relevan, sehingga sangat penting bagi mesin pencari dan sistem rekomendasi. Sebagai contoh, mesin pencari menggunakan LLM untuk memahami pertanyaan pengguna dan mengambil halaman web yang paling relevan dari indeksnya.
Analisis sentimen:
Bisnis memanfaatkan LLM untuk mengukur sentimen publik di media sosial dan ulasan pelanggan. Hal ini memfasilitasi riset pasar dan manajemen merek dengan memberikan wawasan tentang opini pelanggan. Misalnya, LLM dapat menganalisis postingan media sosial untuk menentukan apakah postingan tersebut mengekspresikan sentimen positif atau negatif terhadap suatu produk atau layanan.
Kecerdasan Buatan Percakapan dan chatbot:
LLM memberdayakan AI percakapan dan chatbot untuk berinteraksi dengan pengguna dengan cara yang alami dan seperti manusia. Model-model ini dapat melakukan percakapan berbasis teks dengan pengguna, menjawab pertanyaan, dan memberikan bantuan. Misalnya, asisten virtual yang diberdayakan oleh LLM dapat membantu pengguna dengan tugas-tugas seperti mengatur pengingat atau menemukan informasi.
Terkait harus dibaca:
- AI percakapan – Panduan lengkap untuk [2024]
- Chatbot AI – Panduan lengkap untuk chatbot
- Bot Suara – Panduan lengkap untuk bot suara
Klasifikasi dan kategorisasi:
LLM mahir dalam mengklasifikasikan dan mengkategorikan konten berdasarkan kriteria yang telah ditentukan. Misalnya, mereka dapat mengkategorikan artikel berita ke dalam topik-topik seperti olahraga, politik, atau hiburan, sehingga membantu dalam pengorganisasian dan rekomendasi konten.
Keterangan gambar:
LLM multimodal dapat menghasilkan teks deskriptif untuk gambar, sehingga membuatnya berharga untuk aplikasi seperti pembuatan konten, aksesibilitas, dan pencarian gambar. Misalnya, dengan gambar Menara Eiffel, LLM multimodal dapat menghasilkan teks seperti, “Pemandangan Menara Eiffel yang menakjubkan dengan latar belakang langit biru yang cerah.”
Penerjemahan Bahasa-Gambar:
Model ini dapat menerjemahkan deskripsi teks ke dalam gambar atau sebaliknya. Misalnya, jika pengguna mendeskripsikan sebuah pakaian, LLM multimodal dapat menghasilkan gambar yang sesuai yang menangkap esensi dari deskripsi tersebut.
Visual Question Answering (VQA):
LLM multimodal unggul dalam menjawab pertanyaan tentang gambar. Dalam skenario VQA, ketika disajikan gambar kucing dan ditanya, “Hewan apa yang ada di gambar?” model dapat merespons dengan “kucing.”
Rekomendasi produk dengan isyarat visual
Dalam e-commerce, LLM multimodal dapat merekomendasikan produk dengan mempertimbangkan deskripsi produk tekstual dan gambar. Jika pengguna mencari “sepatu kets merah”, model dapat menyarankan sepatu kets merah berdasarkan pengenalan gambar dan informasi tekstual.
Pembuatan konten visual otomatis:
Dalam desain grafis dan pemasaran, LLM multimodal dapat secara otomatis menghasilkan konten visual, seperti postingan media sosial, iklan, atau infografis, berdasarkan input tekstual.
Manfaat model bahasa besar (LLM)
Manfaat yang ditawarkan oleh LLM mencakup berbagai aspek:
- Efisiensi: LLM mengotomatiskan tugas-tugas yang melibatkan analisis data, mengurangi kebutuhan akan intervensi manual dan mempercepat proses.
- Skalabilitas: Model-model ini dapat diskalakan untuk menangani volume data yang besar, sehingga mudah beradaptasi dengan berbagai aplikasi.
- Kinerja: LLM era baru dikenal dengan kinerjanya yang luar biasa, ditandai dengan kemampuan untuk menghasilkan respons yang cepat dan latensi rendah.
- Fleksibilitas penyesuaian: LLM menawarkan fondasi yang kuat yang dapat disesuaikan untuk memenuhi kasus penggunaan tertentu. Melalui pelatihan tambahan dan penyempurnaan, perusahaan dapat menyesuaikan model ini agar sesuai dengan kebutuhan dan tujuan mereka yang unik.
- Dukungan multibahasa: LLM dapat bekerja dengan berbagai bahasa, mendorong komunikasi global dan akses informasi.
- Pengalaman pengguna yang lebih baik: LLM meningkatkan interaksi pengguna dengan chatbot, asisten virtual, dan mesin pencari, memberikan respons yang lebih bermakna dan sesuai konteks.
Keterbatasan dan tantangan model bahasa besar (LLM)
Meskipun LLM menawarkan kemampuan yang luar biasa, namun LLM juga memiliki keterbatasan dan tantangan tersendiri:
- Amplifikasi bias: LLM dapat mengabadikan bias yang ada dalam data pelatihan, yang mengarah pada keluaran yang bias atau diskriminatif.
- Masalah etika dan halusinasi: LLM dapat menghasilkan konten yang berbahaya, menyesatkan, atau tidak pantas, sehingga menimbulkan masalah etika dan moderasi konten.
- Hasil yang dapat ditafsirkan: Memahami mengapa LLM menghasilkan teks tertentu dapat menjadi tantangan, sehingga sulit untuk memastikan transparansi dan akuntabilitas.
- Privasi data: Menangani data sensitif dengan LLM memerlukan langkah-langkah privasi yang kuat untuk melindungi informasi pengguna dan menjaga kerahasiaan.
- Biaya pengembangan dan operasional: Menerapkan LLM biasanya memerlukan investasi besar dalam perangkat keras unit pemrosesan grafis (GPU) yang mahal dan kumpulan data yang luas untuk mendukung proses pelatihan.
Di luar fase pengembangan awal, biaya operasional berkelanjutan yang terkait dengan menjalankan LLM untuk sebuah organisasi bisa sangat tinggi, termasuk biaya pemeliharaan, sumber daya komputasi, dan energi.
- Token kesalahan: Penggunaan petunjuk yang dirancang dengan jahat, yang disebut sebagai token kesalahan, berpotensi mengganggu fungsionalitas LLM, menyoroti pentingnya langkah-langkah keamanan yang kuat dalam penerapan LLM.
Jenis-jenis model bahasa besar (LLM)
Berikut ini adalah ringkasan dari empat jenis model bahasa besar yang berbeda:
- Bidikan nol: Model zero-shot adalah LLM standar yang dilatih pada data umum untuk memberikan hasil yang cukup akurat untuk kasus penggunaan umum. Model-model ini tidak memerlukan pelatihan tambahan dan siap untuk segera digunakan.
- Disempurnakan atau khusus untuk domain tertentu: Model yang disempurnakan melangkah lebih jauh dengan menerima pelatihan tambahan untuk meningkatkan efektivitas model zero-shot awal. Contohnya adalah OpenAI Codex, yang sering digunakan sebagai alat pemrograman pelengkapan otomatis untuk proyek-proyek yang dibangun di atas fondasi GPT-3. Ini juga disebut LLM khusus.
- Representasi bahasa: Model representasi bahasa memanfaatkan teknik pembelajaran mendalam dan transformer, dasar arsitektur AI generatif. Model-model ini sangat cocok untuk tugas pemrosesan bahasa alami, memungkinkan konversi bahasa ke dalam berbagai media, seperti teks tertulis.
- Multimodal: LLM multimodal memiliki kemampuan untuk menangani teks dan gambar, yang membedakannya dari pendahulunya yang terutama dirancang untuk menghasilkan teks. Contohnya adalah GPT-4V, iterasi multimodal yang lebih baru dari model ini, yang mampu memproses dan menghasilkan konten dalam berbagai modalitas.
Strategi evaluasi untuk model bahasa besar
Setelah menjelajahi cara kerja LLM, kelebihan, dan kekurangannya, langkah selanjutnya adalah mempertimbangkan proses evaluasi Strategi evaluasi untuk model bahasa besar
- Pahami kasus penggunaan Anda: Mulailah dengan mendefinisikan tujuan Anda dengan jelas dan tugas spesifik yang Anda inginkan untuk dilakukan oleh LLM. Pahami sifat pembuatan konten, pemahaman bahasa, atau pemrosesan data yang diperlukan.
- Kecepatan dan ketepatan inferensi: Kepraktisan adalah kunci ketika mengevaluasi LLM. Pertimbangkan kecepatan inferensi untuk kumpulan data yang besar; pemrosesan yang lambat dapat menghambat pekerjaan. Pilih model yang dioptimalkan untuk kecepatan atau menangani input yang besar, atau memprioritaskan ketepatan untuk tugas-tugas seperti analisis sentimen, di mana akurasi adalah yang terpenting dan kecepatan adalah yang kedua.
- Panjang konteks dan ukuran model: Ini adalah langkah yang penting, meskipun beberapa model memiliki batas panjang input, model lainnya dapat menangani input yang lebih panjang untuk pemrosesan yang komprehensif. Ukuran model memengaruhi kebutuhan infrastruktur, dengan model yang lebih kecil cocok untuk perangkat keras standar. Namun, model yang lebih besar menawarkan kemampuan yang lebih baik tetapi membutuhkan lebih banyak sumber daya komputasi.
- Tinjau model yang telah dilatih sebelumnya: Jelajahi LLM pra-terlatih yang sudah ada, seperti GPT-4, Claude, dan lainnya. Nilai kemampuan mereka, termasuk dukungan bahasa, keahlian domain, dan kemampuan multibahasa, untuk mengetahui apakah mereka sesuai dengan kebutuhan Anda.
- Opsi penyempurnaan: Evaluasi apakah penyempurnaan LLM diperlukan untuk menyesuaikannya dengan tugas-tugas spesifik Anda. Beberapa LLM menawarkan opsi penyempurnaan, sehingga Anda dapat menyesuaikan model untuk kebutuhan unik Anda.
- Pengujian dan evaluasi: Sebelum membuat keputusan akhir, lakukan pengujian dan eksperimen dengan LLM untuk mengevaluasi kinerja dan kesesuaiannya dengan tugas-tugas spesifik Anda. Hal ini dapat melibatkan menjalankan proyek percontohan atau melakukan uji coba konsep. Seperti menilai keluaran LLM terhadap referensi berlabel yang memungkinkan penghitungan metrik akurasi.
- Pertimbangan etika dan keamanan: Kaji implikasi etika dan keamanan, terutama jika LLM akan menangani data sensitif atau menghasilkan konten yang mungkin memiliki implikasi hukum atau etika.
- Mengevaluasi biaya: Pertimbangkan biaya yang terkait dengan penggunaan LLM, termasuk biaya lisensi, sumber daya komputasi, ukuran model, dan biaya operasional yang sedang berlangsung. Manfaatkan metode pengoptimalan seperti kuantisasi, akselerasi perangkat keras, atau layanan cloud untuk meningkatkan skalabilitas dan menurunkan biaya.
- Lisensi dan penggunaan komersial: Memilih LLM yang tepat melibatkan pertimbangan yang cermat atas persyaratan lisensi. Meskipun beberapa model terbuka memiliki batasan penggunaan komersial, model lainnya mengizinkan aplikasi komersial. Sangat penting untuk meninjau persyaratan lisensi untuk memastikan persyaratan tersebut sesuai dengan kebutuhan bisnis Anda.
Contoh model bahasa besar (LLM) yang populer
1. Model GPT (Generative Pre-trained Transformer):
GPT-3, GPT-4, dan variannya, yang dikembangkan oleh OpenAI, telah mendapatkan popularitas karena kemampuan pembuatan teks dan keserbagunaannya dalam berbagai tugas bahasa. Sekarang dengan GPT-4V, GPT-4V merambah ke ruang LLM multimodal.
2. BERT (Representasi Encoder Dua Arah dari Transformer):
Dikembangkan oleh Google, BERT terkenal dengan kemampuannya untuk memahami konteks secara dua arah, menjadikannya bahan pokok dalam tugas-tugas NLP.
3. Claude:
Dikembangkan oleh Anthropic, Claude secara khusus dirancang untuk menekankan AI konstitusional. Pendekatan ini memastikan bahwa keluaran AI Claude mematuhi serangkaian prinsip yang ditentukan, sehingga asisten AI yang diberdayakannya tidak hanya membantu tetapi juga aman dan akurat.
4. LLaMA (Large Language Model Meta AI):
Meta’s 2023 LLM, menawarkan versi 65 miliar parameter yang sangat besar. Awalnya dibatasi untuk peneliti dan pengembang yang disetujui, sekarang menjadi open source, menawarkan varian yang lebih kecil dan lebih mudah diakses.
5. PaLM (Pathways Language Model):
PaLM Google adalah model berbasis transformator dengan 540 miliar parameter yang sangat besar yang menggerakkan chatbot AI Bard. PaLM mengkhususkan diri dalam tugas-tugas penalaran seperti pengkodean, matematika, klasifikasi, dan menjawab pertanyaan. Beberapa versi yang telah disempurnakan tersedia, termasuk Med-Palm 2 untuk ilmu hayati dan Sec-Palm untuk mempercepat analisis ancaman dalam penerapan keamanan siber.
6. Orca:
Kreasi Microsoft dengan 13 miliar parameter, dirancang untuk berjalan secara efisien bahkan pada laptop. Orca meningkatkan model open source dengan mereplikasi kemampuan penalaran LLM, memberikan performa GPT-4 dengan parameter yang lebih sedikit, dan menyamai GPT-3.5 dalam berbagai tugas. Orca didasarkan pada versi 13 miliar parameter LLaMA.
Model Bahasa Besar ini telah membentuk kembali lanskap pemrosesan bahasa alami, memungkinkan kemajuan terobosan dalam komunikasi, pencarian informasi, dan kecerdasan buatan.
Namun demikian, untuk penggunaan perusahaan, LLM generik, meskipun mengesankan, sering kali tidak memiliki kedalaman dan nuansa yang diperlukan untuk domain khusus, sehingga lebih rentan menghasilkan konten yang tidak akurat atau tidak relevan. Keterbatasan ini terutama terlihat dalam bentuk halusinasi atau salah tafsir terhadap informasi spesifik domain. Sebaliknya, LLM yang terspesialisasi atau disesuaikan dengan baik dirancang untuk memiliki pengetahuan mendalam tentang terminologi khusus industri, memungkinkan mereka untuk secara akurat memahami dan menghasilkan konten yang terkait dengan konsep-konsep tertentu yang mungkin tidak dikenali secara universal atau dipahami dengan baik oleh model bahasa umum.
Memanfaatkan LLM khusus tersebut dapat memberikan keunggulan bagi perusahaan yang ingin menggunakan LLM untuk fungsi dan kasus penggunaan yang sangat spesifik berdasarkan data mereka sendiri.
Kesimpulan
LLM mewakili lompatan transformatif dalam kecerdasan buatan, yang didorong oleh skala yang sangat besar dan kemampuan pembelajaran yang mendalam. Model-model ini berakar pada evolusi model bahasa yang berasal dari masa-masa awal penelitian AI. Mereka berfungsi sebagai tulang punggung aplikasi NLP, merevolusi komunikasi dan pembuatan konten.
Meskipun LLM berspesialisasi dalam tugas-tugas yang berhubungan dengan bahasa, mereka sekarang meluas ke domain multimodal, memproses dan menghasilkan konten di seluruh teks, gambar, dan kode. Keserbagunaannya telah menyebabkan adopsi yang luas di berbagai industri, mulai dari bantuan pengkodean hingga pembuatan konten, penerjemahan, dan analisis sentimen. Dan adopsi ini diperkirakan akan terus meningkat dengan adanya LLM khusus, kemampuan multimodal baru, dan kemajuan lebih lanjut dalam bidang ini.
Meskipun sudah menunjukkan dampak yang signifikan dalam hal penggunaan perusahaan di berbagai fungsi dan kasus penggunaan, LLM bukannya tanpa tantangan, termasuk bias dalam data pelatihan, masalah etika, dan masalah interpretasi yang kompleks. Perusahaan harus mengevaluasi model-model ini dengan cermat berdasarkan kasus penggunaan spesifik mereka, dengan mempertimbangkan faktor-faktor seperti kecepatan inferensi, ukuran model, opsi penyempurnaan, implikasi etika, dan biaya. Dengan demikian, mereka dapat memanfaatkan potensi besar LLM untuk mendorong inovasi dan efisiensi dalam lanskap AI, mengubah cara kita berinteraksi dengan teknologi dan informasi.




