






The surprising part of conversational AI design is that the field's oldest lesson is still the one that many in the field disregard. Users don't reward an assistant for sounding most human. They reward it for being clear, predictable, and useful.
That matters more now because conversational AI has moved into the core operating stack. The global conversational AI market was valued at USD 11.58 billion in 2024 and is projected to reach USD 41.39 billion by 2030, growing at a 23.7% CAGR according to Nextiva's conversational AI market summary. Once a capability reaches that level of enterprise adoption, design stops being a layer of polish. It becomes part of service architecture, governance, and risk control.
For CTOs and Heads of CX, that changes the brief. The primary challenge isn't writing friendlier prompts or inventing a memorable bot persona. It's building interactions that can survive ambiguity, security constraints, multilingual demand, model variance, and human escalation at scale. In agentic, multi-LLM systems, conversational AI design now sits much closer to systems engineering than traditional copywriting.
Table of Contents
- The New Imperative in Conversational AI Design
- Foundational Principles of Effective Conversation
- Architecting the Conversation Flow
- Designing for Voice and Multimodal Experiences
- Reliability Over Naturalness The New LLM Design Paradigm
- Enterprise Grade Design Compliance Security and Equity
- Evaluating Design Success and Implementing Governance
The New Imperative in Conversational AI Design
Conversational AI design has entered a different era. The old playbook assumed a contained bot, a narrow channel, and a mostly scripted journey. That worked when teams were automating simple FAQs or routing a small set of repetitive requests.
That assumption breaks in modern enterprise environments. Today's systems span chat, voice, email, agent assist, employee service, and workflow automation. They often rely on multiple models, retrieval layers, tool calls, business rules, and handoffs across human and machine actors. In that context, a conversation isn't just a dialog. It's an execution layer for service delivery.
Design has moved from personality to operational control
The fastest way to spot immature conversational AI design is to look for overinvestment in tone and underinvestment in failure handling. Teams spend weeks refining persona attributes, then discover the assistant can't recover when a user changes intent halfway through a task or challenges an incorrect answer.
Enterprise leaders need a different lens:
- Outcome control: Can the assistant complete the task, or route it cleanly when it can't?
- State discipline: Does it remember what matters, forget what no longer applies, and avoid leaking stale context?
- Operational traceability: Can product, compliance, and support teams inspect what happened and why?
Practical rule: If a conversation can trigger action, it must be designed as a governed workflow, not as free-form chat.
Scale exposes weak design faster than bad demos do
A pilot can hide design debt. Production won't. Once a conversational system supports multiple business units and channels, every ambiguity compounds. Confusing prompts create repeat turns. Loose state handling creates wrong assumptions. Inconsistent outputs create audit pain.
Good conversational AI design now looks less like writing a bot script and more like defining a service contract between the user, the model, enterprise systems, and human operators. That's why design has become a strategic capability. It directly affects containment, trust, reviewability, and cost to serve.
Foundational Principles of Effective Conversation
The field learned this lesson early. As far back as 1966, Joseph Weizenbaum's ELIZA showed that people attribute meaning and empathy based on conversational structure and turn-taking, not just intelligence, as noted in Grand View Research's historical overview of conversational AI. That's still true in enterprise deployments.
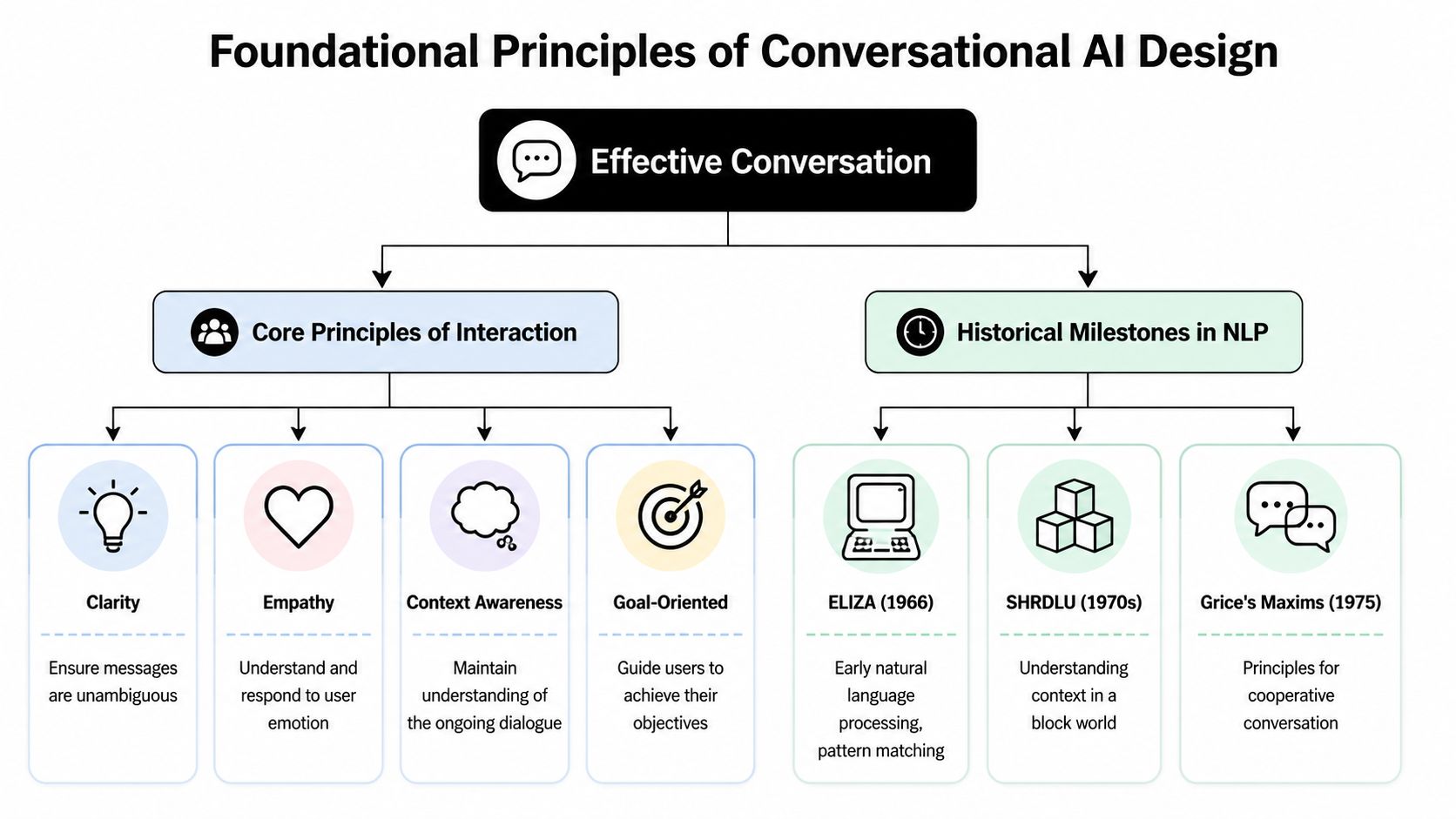
What ELIZA still teaches enterprise teams
ELIZA wasn't powerful by modern standards. Its importance came from showing that users respond strongly to conversational framing. A system with limited intelligence can still feel competent if it manages turns well, acknowledges inputs clearly, and maintains a coherent interaction pattern.
That has two implications for enterprise teams.
First, users judge the assistant on interaction quality long before they understand its architecture. If the assistant interrupts, rambles, asks for the same detail twice, or fails to acknowledge uncertainty, trust drops quickly.
Second, scripted structure still matters even in LLM systems. Pattern matching may be old, but turn discipline, repair prompts, and expectation-setting remain foundational. Generative capability doesn't remove the need for design. It makes design more important because the system now has more ways to go wrong.
Practical rules for cooperative dialogue
A strong conversational system follows the human rules people already expect in dialogue. Grice's maxims remain useful shorthand, even if teams don't formally name them in design reviews.
| Principle | What it means in practice | Common failure mode |
|---|---|---|
| Quality | Say only what the system can support with confidence | The assistant guesses instead of qualifying uncertainty |
| Quantity | Give enough detail to move the task forward | The assistant overloads the user with explanation |
| Relevance | Respond to the user's actual goal, not the closest template | The flow answers a related but wrong question |
| Manner | Keep wording direct, concrete, and easy to parse | The assistant sounds polished but unclear |
These principles become operational heuristics in design work:
- Turn-taking should be deliberate: Ask for one decisive input at a time when the task is sensitive or regulated.
- Context should be earned: Retain what helps the current task. Reconfirm details when risk is high.
- Feedback should be explicit: Users should know whether the system understood them, is processing, needs clarification, or is handing off.
- Expectations should be honest: Don't imply human judgment, authority, or memory the system doesn't have.
A reliable assistant doesn't need to sound human. It needs to sound accountable.
A lot of failed experiences come from violating one of those basics. The assistant provides too much text when a binary confirmation would do. It asks broad questions when a narrow one would reduce ambiguity. It hides uncertainty instead of stating the boundary.
For teams building at enterprise scale, the design baseline is simple. Make the next step obvious. Make the system state visible. Make recovery easy. Those aren't legacy conversation design principles. They're the foundation modern orchestration still sits on.
Architecting the Conversation Flow
The quality of a conversational experience usually depends less on the model than on the flow architecture around it. When teams struggle, the root cause is often structural. The system doesn't know what job the user is trying to complete, what data it has already collected, or what should happen when confidence drops.
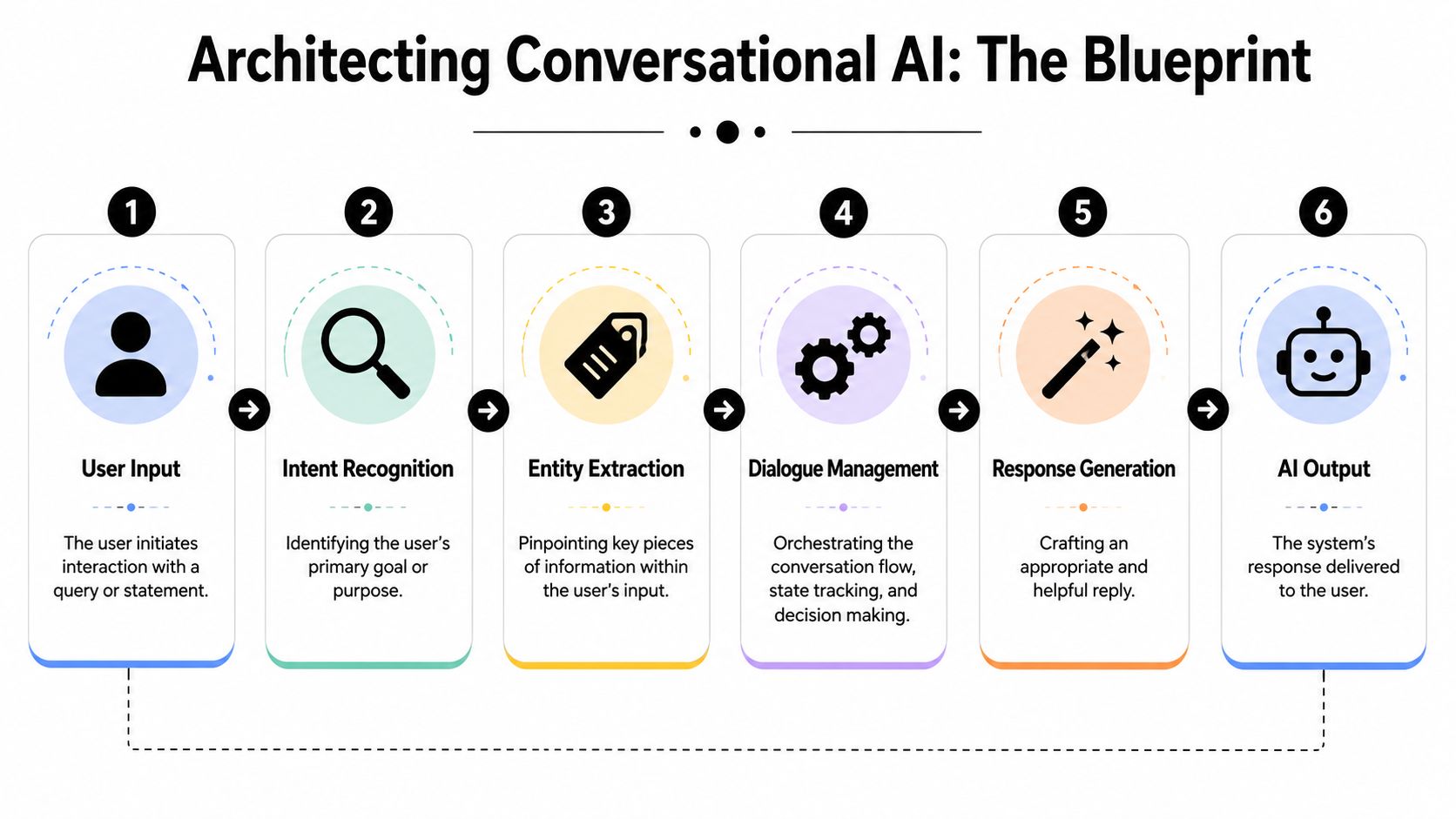
The core objects of a working conversation
At minimum, enterprise conversation architecture has to manage three things well.
Intent is the task the user is trying to accomplish. “Reset my password,” “track my order,” and “change my shift” are different intents even if the wording varies.
Entities are the variables that make the task actionable. That might be a date, account type, order reference, city, or employee ID.
State is the system's understanding of where the interaction stands right now. It includes what has already been confirmed, what is still missing, what policy constraints apply, and whether a human should take over.
If any of those are weak, the entire experience becomes fragile. A bot may identify an intent correctly but fail because it doesn't capture the required entities. Or it may collect the right details but lose the state after the user asks a side question.
A practical flow usually includes these stages:
- Recognition: infer likely intent and confidence.
- Qualification: collect missing information.
- Execution: perform the action or retrieve the answer.
- Confirmation: state what happened in unambiguous terms.
- Recovery or escalation: provide a clear next step when something fails.
For teams evaluating tooling, a platform such as Yellow.ai's AI Agent Builder is relevant when you need to design and test these flows across channels without treating every conversation as bespoke code.
Later in the build cycle, it helps to review a concrete walkthrough of orchestration patterns before rollout.
Where scripted flows still win
There's a tendency to treat rule-based design as outdated. In practice, deterministic flows remain the right choice for many enterprise moments.
Use scripted logic when:
- The action is high risk: payment changes, account access, policy acknowledgments.
- The path is narrow: a finite set of known routes produces better control than open generation.
- Auditability matters: you need to explain exactly why the system asked, blocked, or escalated.
A good decision tree is not a primitive chatbot. It's a controlled service path. The design challenge is to keep it concise enough that users don't feel trapped. Overly branched trees often fail because they expose internal logic instead of user goals.
Where generative systems add value
LLMs become useful when the conversation space is broader or messier. They help with paraphrase handling, summarization, knowledge retrieval, and transitions between intents that would be awkward to script manually.
But the generative layer should sit inside constraints. In enterprise flows, the model shouldn't own every decision. It should support specific functions inside a broader architecture.
A workable division of labor looks like this:
| Task type | Better fit |
|---|---|
| Policy-bound confirmations | Scripted or templated |
| Open-ended question understanding | Generative |
| Data collection with validation | Hybrid |
| Knowledge-grounded explanation | Generative with retrieval |
| Sensitive approval or commitment | Deterministic control |
The strongest conversational AI design uses both. Script where control is essential. Generate where flexibility creates real user value. The mistake is forcing one method to do the work of the other.
Designing for Voice and Multimodal Experiences
Text design habits don't transfer cleanly into voice. A weak chat experience is frustrating. A weak voice experience feels broken almost immediately because users can't scan, reread, or visually inspect options.
Voice changes the tolerance for bad design
In voice, latency becomes part of the interface. If the system takes too long to respond, users assume it didn't hear them. If it responds too quickly with the wrong interpretation, they assume it's careless.
That creates a narrow design envelope. Prompts must be shorter, confirmations cleaner, and repair paths more forgiving. You also need tighter control over interruption handling, barge-in behavior, and fallback wording.
For enterprise teams deploying voice automation, Yellow.ai's voice bot capabilities are one example of the kind of stack to evaluate when low-latency orchestration, telephony integration, and voice-specific flow design matter.
A few voice rules hold up across industries:
- Front-load meaning: Put the key action at the beginning of the utterance.
- Avoid list overload: Spoken menus collapse when there are too many similar options.
- Confirm selectively: Confirm high-risk details, not every trivial step.
- Design for ASR imperfection: Users should be able to correct recognition errors naturally.
Multimodal design should show users the next move
Multimodal systems create a bigger opportunity than is often realized. If the user speaks a product search, the assistant doesn't need to read every option aloud. It can summarize the result in voice and display a carousel, form, map, image, or quick-reply set on the screen.
That's where channel orchestration matters. The same service logic should adapt to modality rather than cloning separate experiences for each surface.
In multimodal design, the best response is often not a better sentence. It's a better next action on screen.
A practical way to think about modality choice is this:
| User need | Best delivery mode |
|---|---|
| Quick reassurance or status | Voice or text |
| Comparison across options | Visual card or carousel |
| Complex policy explanation | Short text with expandable details |
| Identity verification | Guided handoff or secure UI step |
| Step-by-step troubleshooting | Mixed mode with text, images, and confirmation buttons |
The main failure pattern here is duplication. Teams make the voice layer say everything the visual layer already shows. That increases friction and call time. Better design splits responsibility. Voice keeps momentum. Visuals carry complexity.
The same principle applies in employee service and contact centers. Don't force users to stay in one mode if the task would benefit from another. Good multimodal conversational AI design makes the transition feel intentional rather than patched together.
Reliability Over Naturalness The New LLM Design Paradigm
The biggest design mistake in the LLM era is still treating human-likeness as the primary success criterion. That may be fine for novelty use cases. It's the wrong objective for enterprise service.
Modern guidance increasingly emphasizes correction, verification, and controlled failure, including external knowledge bases, turn-level feedback, and natural-language error correction, according to Smashing Magazine's guide to effective conversational AI experiences. That shift is overdue.
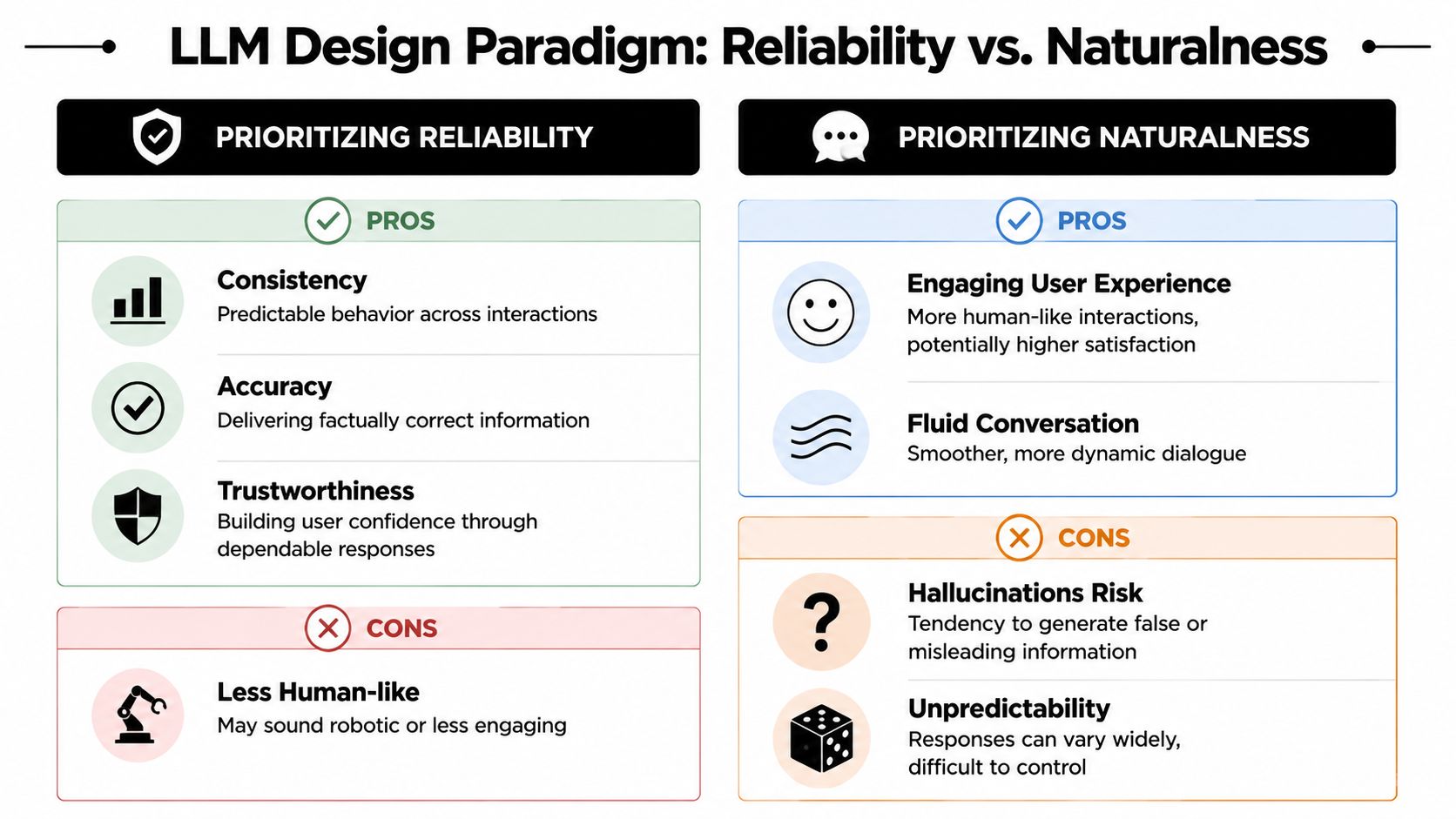
Why naturalness is the wrong north star
A natural-sounding response can still be a poor enterprise response. In fact, naturalness often masks failure because users lower their guard when the assistant sounds fluent.
What matters more is whether the system can do four things consistently:
- State its limits
- Ground answers in approved knowledge
- Accept correction without derailment
- Fail in a way that preserves progress
That changes the design brief. Instead of asking, “How do we make this feel more human?” ask, “How do we make this easier to verify, recover, and monitor?”
Consider the difference:
| Design goal | Weak enterprise outcome | Strong enterprise outcome |
|---|---|---|
| More human tone | Pleasant but inconsistent answers | Controlled tone within approved boundaries |
| Open-ended flexibility | Greater variance and hidden errors | Flexibility only where it improves task completion |
| Fewer visible constraints | Users can't tell when the system is unsure | Boundaries are explicit and manageable |
Design patterns that make LLM systems governable
The most effective pattern is to treat each response as a controllable artifact. Teams can encode compact style tokens in prompts, maintain approved microcopy for confirmations and escalations, and run automated checks in CI so drift fails before release, as described in Bland.ai's discussion of testable conversation design.
That one idea has deep consequences. It means conversation quality is no longer something you only judge manually after launch. It becomes a build-time concern.
The design patterns worth operationalizing are straightforward:
- Grounded response generation: Pull from an external knowledge source when the answer must be factual or policy-bound.
- Turn-level correction: Let users say “No, that's not what I meant” or restate an input without losing the rest of the session.
- Tiered failure behavior: Distinguish between uncertainty, tool failure, policy block, and escalation need.
- Protected microcopy: Lock language for disclosures, confirmations, sensitive notices, and handoff statements.
- Output testing: Compare generations against approved patterns before promoting changes.
Design principle: Every enterprise assistant needs a repair grammar. If users can't correct it naturally, the system isn't production-ready.
This is especially important in agentic, multi-LLM environments. Once multiple models, retrieval steps, and tools interact, bugs stop looking like simple answer errors. They become orchestration defects. A sub-agent uses stale context. A retrieval layer returns outdated guidance. A planner chooses the wrong tool. Without deliberate conversational design, those failures are hard to expose and harder to explain.
That's why reliability beats naturalness. Not because users dislike fluid interaction. Because enterprise systems need behavior that operations, compliance, and support teams can inspect and trust.
Enterprise Grade Design Compliance Security and Equity
Enterprise conversation design has to absorb constraints that consumer demos rarely show. A production assistant may handle account recovery, employee records, claims status, payments, benefits questions, or regulated disclosures. In those environments, design errors become security events, compliance gaps, or exclusion problems.
Compliance has to shape the flow
Too many teams treat compliance as a review step at the end. In practice, it should shape the interaction model from the start.
A few examples illustrate the point:
- Authentication timing: Don't ask users for sensitive details before the system has established the right verification state.
- Data minimization: Collect only what the task requires. Extra collection increases risk and often degrades usability.
- Masked confirmation design: Users may need reassurance that a record was found without exposing full sensitive fields in the transcript.
- Escalation boundaries: Some actions should route to a human or secure application step rather than remain in conversational mode.
Platform capability matters. If your operating model requires auditable controls, secure deployment patterns, and enterprise certifications, teams usually evaluate options such as Yellow.ai's enterprise-grade security framework alongside their broader architecture.
A useful rule is to classify every conversational turn into one of three categories: safe to answer, safe to collect, or must hand off. That sounds simple, but it forces the design team to stop treating all turns as equivalent.
Equity-by-design is an operating requirement
One of the most overlooked issues in conversational AI design is who the system implicitly excludes. Research in health-focused conversational AI recommends needs assessment up front, measurable equity outcomes before build, co-design with communities, native-language support, and user input on persona and style, as discussed in PLOS Digital Health's equity-by-design recommendations.
That guidance applies well beyond healthcare. Global enterprises serve users across languages, literacy levels, age groups, cultures, and cognitive contexts. If the assistant only works for fluent, digitally confident users, the design has failed even if the analytics dashboard looks healthy.
The commercial impact is direct:
- Language quality affects trust: Translation errors don't feel cosmetic when they distort policy or status information.
- Persona affects acceptance: A style that works in one region may feel dismissive or overly casual in another.
- Cognitive load affects completion: Dense messages punish users who are stressed, distracted, or unfamiliar with the process.
Build for the edges first. The middle usually takes care of itself.
Equity-by-design doesn't require abstract ethics language. It requires operational choices. Test with native speakers. Validate tone locally, not just centrally. Offer simpler phrasing where the task is already stressful. Let users steer the level of detail. Avoid assuming shared idioms or cultural context.
The most mature teams now treat inclusion as a quality dimension of the product, not as a side initiative. That's the right enterprise posture. A conversational system that serves only the easiest users will drive hidden costs back into human channels.
Evaluating Design Success and Implementing Governance
Many still overindex on satisfaction signals because they're visible and easy to collect. That's useful, but it's not enough. A conversational system can generate polite feedback while still failing operationally through unnecessary handoffs, repeated clarifications, and brittle behavior around exceptions.
Measure outcomes not charm
The evaluation model should begin with task success. Did the user complete the intended job with acceptable effort and acceptable risk?
That means reviewing a fuller set of indicators, such as:
- Task completion rate: Whether the user reached the intended outcome.
- Containment by intent: Which requests the assistant can resolve without human intervention.
- First-contact resolution: Whether the issue was actually settled, not merely routed.
- User effort: How much work the user had to do to get there.
- Error recovery quality: Whether the system preserved momentum after misunderstandings or tool failures.
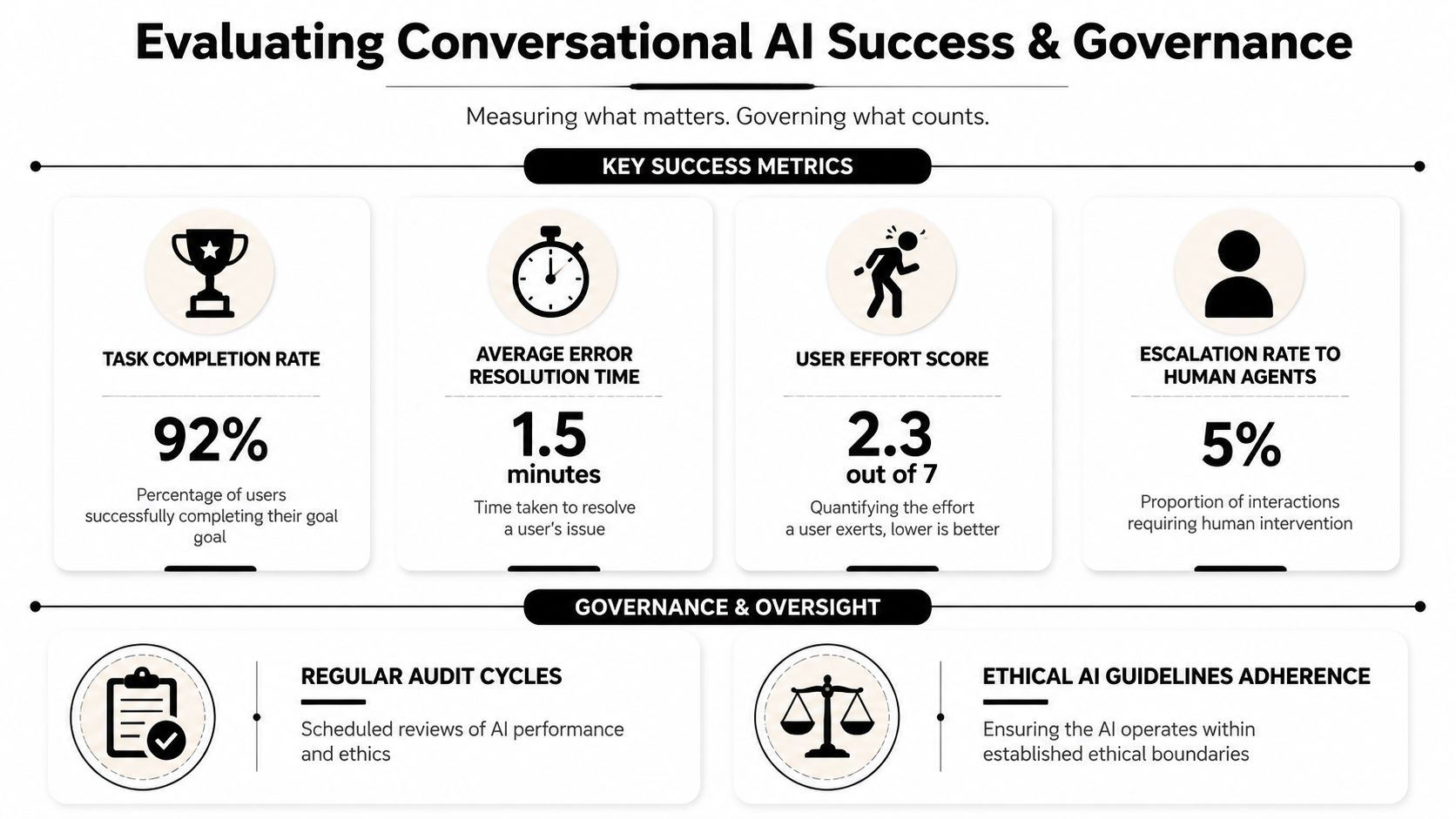
The point isn't to create more reporting for its own sake. It's to distinguish between conversational polish and operational performance. If users consistently complete tasks but dislike the tone, that's a copy problem. If they like the assistant but still escalate frequently, that's a design and systems problem.
Governance needs operating mechanics
Governance works when it's embedded in release management, not when it lives in a policy deck. For modern conversational AI design, that usually means a recurring discipline around review, testing, ownership, and retirement.
A practical governance rhythm includes:
| Governance area | What strong teams do |
|---|---|
| Prompt and flow versioning | Track changes like product releases, with rollback options |
| Pre-release testing | Test key intents, failure paths, and protected language before deployment |
| Post-release monitoring | Review drift, correction patterns, escalation reasons, and unresolved intents |
| Ownership model | Assign clear responsibility across design, engineering, operations, and compliance |
| Lifecycle management | Retire outdated flows and knowledge sources before they create silent errors |
The biggest shift is cultural. Teams have to stop treating conversational AI as a one-time launch. It's a living service layer with ongoing tuning, auditing, and scope control.
That's where a lot of enterprise value is won or lost. Strong design creates measurable operational advantage only when governance keeps the behavior stable as channels, models, and business rules evolve.
Yellow.ai fits into this conversation as an enterprise option for teams that need one platform to design, test, deploy, and govern conversational AI across CX and EX channels, including voice, chat, multimodal orchestration, analytics, and compliance-oriented controls. For organizations moving from isolated bots to governed agentic systems, that kind of platform approach can reduce fragmentation and make conversation design easier to operationalize across business units.



