





PRISM is a research effort from the team at Yellow.ai, and we hope it gives the field a foundation for continuous prompt reliability in production AI systems.
Introduction
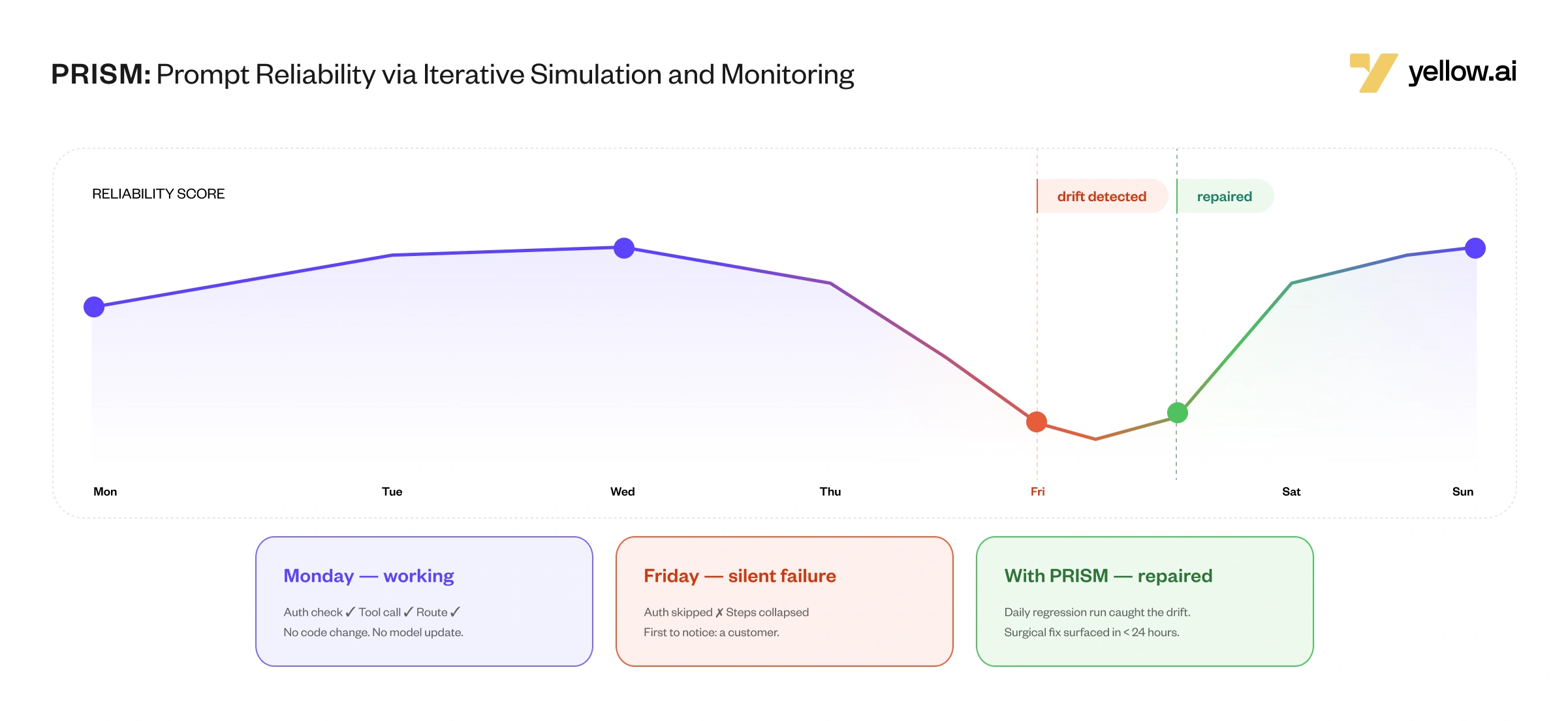
A prompt can silently drift from reliable to inconsistent behavior without any visible changes behind the scenes. The agent still answers. It just stops following the procedure. And the first person to notice is usually a customer.
This is the uncomfortable reality of running a large language model (LLM)–driven agents in production. Most of the industry treats prompt engineering as a one-time authoring task: write it, test it, ship it, move on. But after building and operating dozens of enterprise agents on the Yellow.ai V3 platform, we’ve found that the harder problem isn’t writing a correct prompt , it’s keeping it correct.
That’s why we built PRISM (Prompt Reliability via Iterative Simulation and Monitoring): a closed-loop framework that treats prompt engineering not as authorship, but as continuous reliability engineering.
The Problem Nobody Talks About: Prompts Don’t Stay Correct
Enterprise conversational agents , cancellation flows, onboarding assistants, billing-dispute handlers , aren’t general-purpose chatbots. They have to follow precise operational sequences: authenticate the user before proceeding, call a specific workflow with specific parameters, route to a human under specific conditions, never reveal internal state, use exact prescribed phrasing in regulated contexts.
The natural-language instructions encoding all of this , the frontend agent prompt , are the source of truth for what the agent is supposed to do. And they fail in subtle, operationally expensive ways.
But there’s a second, deeper challenge the industry has largely ignored: LLM behavioral drift. Even pinned model versions accessed through an API don’t behave identically over time. Temperature, sampling variation, and undisclosed inference-layer changes at the provider level mean a prompt that scores 100% correct today can silently degrade over days or weeks , producing real failures, in production, for real users. Enterprises today have no systematic way to detect, localize, or repair this drift before it reaches a customer.
Existing prompt optimization frameworks don’t close this gap. Approaches like DSPy, OPRO, and APE are valuable contributions, but they share one assumption: the optimization target is fixed at compile time, and the resulting prompt is a static artifact. None of them model the multi-turn, tool-integrated environment enterprise agents actually operate in , and none address the ongoing maintenance problem of production drift.
Why Writing a Correct Enterprise Prompt Is So Hard
Across our study of 35 enterprise agents, we found that failures cluster into four dominant classes. These aren’t hallucinations or factual mistakes , the model knows the right answer. They’re failures of procedural compliance.
- Tool call skipping: An authentication check never runs, accidentally exposing sensitive billing data to an unverified user.
- Rule violation , the agent ignores an explicit constraint in the prompt. Example: revealing internal variable names to the user.
- Step reordering , the agent performs steps out of sequence. Example: asking for a cancellation reason before checking eligibility.
- Step collapsing: The agent panics and routes directly to a human agent, completely defeating the purpose of self-service automation.
Each one produces a visibly poor experience and carries direct brand risk. And each one can appear after launch, introduced not by a developer but by drift.
Prompt Reliability Is a Two-Phase Problem
The key reframe behind PRISM is splitting prompt reliability into two distinct phases that the industry usually conflates:
Phase 1 , Creation-time correctness. Given a set of requirements and a draft prompt, can we produce a prompt that passes every test derived from those requirements?
Phase 2 , Runtime reliability. Once that verified prompt is deployed, does it keep passing those tests over time , and when it doesn’t, can we detect and repair the regression fast?
Existing frameworks address only Phase 1. PRISM treats both phases as instances of the same loop, running on different schedules.
Inside PRISM: A Closed Loop for Prompt Reliability
PRISM takes plain-language agent requirements, a set of configured tools and memory variables, and an initial draft prompt. From there it runs a continuous five-stage loop.
1. Requirement-driven test generation. PRISM automatically derives a structured test suite from the requirements document. Each test case contains a realistic multi-turn conversation script, a set of objectively verifiable pass criteria (for example, “agent calls the product-details tool before asking for a cancellation reason”), and mock tool responses calibrated to each tool’s declared return schema. Tests deliberately span the happy path, boundary conditions, error paths, and compliance scenarios. Operators can edit, add, or remove cases to inject domain knowledge the requirements don’t capture.
Example test case : subscription cancellation. Conversation script: user says “I want to cancel my plan.
” Pass criteria: (a) the agent calls getProductDetailsForCancel before asking for a cancellation reason; (b) when the returned zuoraStatus is Cancelled, the agent routes to the Billing Agent rather than continuing self-service. Mock override: getProductDetailsForCancel returns { zuoraStatus: “Cancelled” }, which deliberately forces the boundary branch instead of the happy path.
2. Platform-faithful simulation. PRISM replicates the exact two-layer prompt architecture of production Yellow.ai V3 deployments. It replays each conversation script turn by turn, intercepts the agent’s tool calls, and substitutes per-test mock responses instead of touching the live workflow. The result is deterministic, repeatable test execution against an environment structurally identical to production , without ever risking the live bot.
Example: When the agent calls getProductDetailsForCancel, the simulator never hits the real billing system. It returns the test’s mock value , zuoraStatus: “Cancelled” for one test, zuoraStatus: “Active” for another , so a single conversation script can exercise every conditional branch deterministically. Routing is detected by scanning the bot’s output for the platform marker [ROUTE TO: Billing Agent].
3. LLM-as-judge evaluation. Each transcript is evaluated against its pass criteria by a judge model that sees the full conversation, the tool-call log, and the routing events. The judging is deliberately strict: “a tool call happened” means the tool actually appears in the call log , not that the bot’s wording implied it might have. That strictness is what makes the optimization signal trustworthy.
Example: If the bot says “Let me pull up your account details…” but no getProductDetailsForCancel entry exists in the tool-call log, the judge returns FAIL on criterion (a) , a polite sentence is not a tool call.
Conversely, the bot can phrase things imperfectly and still PASS, as long as the log and routing events satisfy every criterion.
4. Diagnosis and surgical repair. When tests fail, PRISM diagnoses the root cause,identifying exactly which section of the prompt failed and why. It then repairs only the responsible sections while preserving the parts that work.
Example: A tool-call skip.
Diagnosis: the cancellation test fails because the step-sequence section says “help the user cancel their subscription” but never explicitly instructs the agent to call getProductDetailsForCancel first , so the model collapses straight to asking for a reason.
Surgical repair: PRISM rewrites only that step, adding an explicit, ordered instruction to invoke the tool and gate the next step on its result , leaving the routing, confidentiality, and language sections untouched.
Lesson learned the hard way: Early experiments with full prompt rewrites tended to fix failing tests while breaking previously passing ones. Surgical repair ensures monotonic improvement, the prompt only gets better, never sliding backward.
5. Continuous monitoring. Once a prompt passes everything and is deployed, PRISM re-runs the full suite against the production prompt daily. If a previously passing test starts failing, that’s treated as a drift event , it re-enters the repair loop, and a patched prompt is surfaced to the operator within a 24-hour window. Behavioral drift becomes an operational concern handled like a software regression: not anticipated in advance, but detected fast and repaired automatically.
What We Found Across 35 Enterprise Agents
The reliability gap in enterprise conversational AI is often blamed on model capability. Our results point somewhere else: it’s a methodology gap. The field has lacked systematic tools for verifying, monitoring, and maintaining the correctness of multi-step agent behavior over time.
The takeaways for anyone running agents in production:
- Treat prompts like production software, not documents
They regress. They need a test harness, version history, and a deployment safety net , just like code. - Test the whole conversation, not the last reply
Procedural failures hide in tool calls, routing decisions, and step ordering , not in whether the final sentence sounds right. - Monitor continuously
Drift is not a hypothetical. It happened seven times in three weeks across our fleet. Without a daily regression harness, every one of those would have been discovered by a customer first. - Repair surgically
Regenerating a whole prompt to fix one failure usually trades a known bug for an unknown one.
Continuous, simulation-driven prompt optimization isn’t just tractable , at enterprise scale, it’s necessary. This is the same philosophy behind how we think about automated testing and reliable agent deployment on the Yellow.ai platform: AI reliability isn’t about perfect models, it’s about predictable behavior you can trust on day 100 as much as day one.



