
















We’re bringing you our last feature this Friday and the best, yet.
It’s been an eventful year. A strange one to say the least. At Yellow.ai, we’ve pushed boundaries and set benchmarks in the process of helping businesses and enterprises alike to digitize and continue operations during these tough times of the pandemic.
We’re especially proud of the team for making it happen. Because of which Gartner recognizes us as the leading conversational AI platform, advanced virtual assistant provider for enterprises, and a key vendor in customer experience automation and all this because of our exceptional platform and its attributes. Today, we’re discussing Intelligent Content Processing that got us in the Gartner Report – 2021 Strategic Roadmap for Enterprise AI: Natural Language Architecture along with industry giant IBM Watson.
“Priority 1 for enterprises for AI adoption – Combine the use of insight engines (search/discovery) and conversational systems: Use these to provide additional touchpoints to insight (for insight engines integrating with conversational systems including IBM Watson Discovery Service) or intelligent content processing, for conversational platforms assimilating insight engine capabilities to their platforms e.g., Yellow.ai.” – Gartner
Why intelligent content processing?
When an enterprise has a large data pool, comes the requirement of Intelligent Content Processing. It is common for our enterprise customers to have documents shared on Sharepoint or similar data hubs. Most data is in silos, making the task of consolidating and structuring the data very difficult. But what good is data and content that is not in a usable format? This is where Intelligent Content Processing comes into play.
Gartner states that “By 2022, the amount spent on data labeling and annotation services to mark up speech and documents/text will triple from today’s levels.”
Using Yellow.ai’s Conversational AI Platform, enterprises can connect their data hubs and our platform’s document cognition engine reads through all the data and turns it into Questions and Answers, which can be asked and delivered on a conversational layer – web or PWA app or any messaging channel.
What is intelligent content processing?
Intelligent Content Processing via the Document Cognition engine is a way to process unstructured textual data. Document cognition leverages artificial intelligence, machine learning, cognitive science, and natural language processing to index structured, semi-structured, and unstructured data.
When is intelligent content processing via Document Cognition leveraged by a virtual assistant?
When an enterprise is dealing with a lot of documents containing mostly (~70%) text. It is humanly not possible to convert this data into a structured format that can be fed into a system, or a chatbot, or even handled manually. In such cases, we can still leverage this knowledge by feeding it to the document cognition engine, so that the model can directly search for the most relevant responses from within these documents. In such cases, the chatbot can take us to the right page/paragraph with ~75-85% accuracy.
How does intelligent content processing via Document Cognition work?
We can divide document Cognition processing in a chatbot into 3 steps:
#1. Mapping
The first step involves mapping all the documents from different sources and in various formats, such as pdf, doc file, system depository, excel. It then indexes each document with a unique identifier code in real-time and maps this unique identifier code to the unique ID of the Knowledge management system.
#2. Parsing
Post mapping, the bot needs to read and understand what the document is talking about. For this, a parser is placed in the bot. The parser identifies every document and its content (even different sections inside the document) in real-time.
This is similar to how when you search for any keyword on Google, it shows all the documents containing the keyword.
Yellow.ai has developed its own parser to perform a meticulous search of every document.
#3. Training
Now the parsed documents are grouped into entities and then passed through multiple proprietary ML models.
Yellow.ai bot performs a Semantic-based search for the most relevant results for every FAQ question or documents searches.
Reasons for leveraging Intelligent Content Processing via Document Cognition
Knowledge Management
The virtual assistant indexes all the unstructured documents and analyses them. This helps enterprises in managing their data and accessing the documents by just asking the bot, rather than going through multiple documents to find the right solution.
Save Time and Effort
Agents and HR spend several hours browsing many documents to answer a customer or an employee. A Faq chatbot integrated with document cognition can help save a lot of time and effort. This enables the recruiter to focus on more crucial questions.
Reduced risk of regulatory breaches
As the whole knowledge base is saved and automated, it reduces the chances of data being lost or being misfiled.
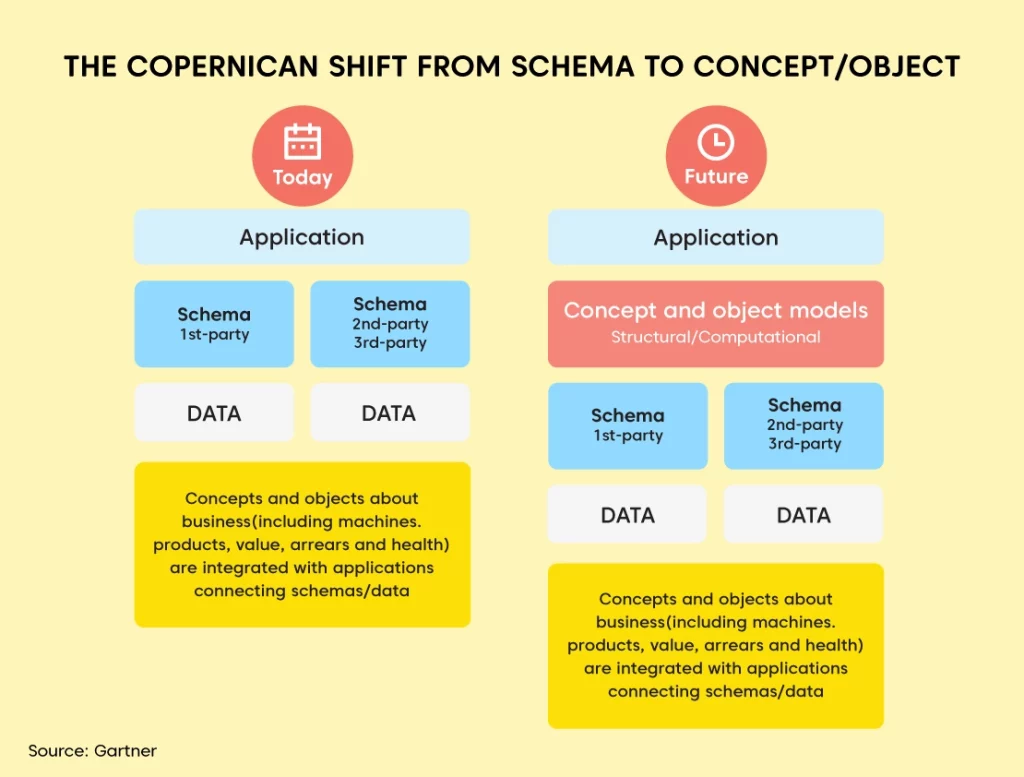
Copernicus has introduced in the 15th century the shift from an earth-centric to a sun-centric view of the solar system. There is a shift underway, the Copernican shift, in how enterprises handle data. The way the data is perceived and how the basic process of Knowledge management is under disruption. The only question that remains is: are you a part of this disruption?
Yellow.ai got mentioned in 6 Gartner reports for our platform and its attributes like Natural Language Intelligent Processing, Artificial Intelligence, Document Cognition to name a few.




